The Case Against Feature Flags: When Toggles Become Technical debt
Feature flags are a lifesaver for shipping fast, testing safely, and rolling out features smoothly. We know - because we use them all the time. But here’s the thing: when they overstay their welcome, they turn into a mess. Cluttering your code, making debugging harder, and slowing development.
What starts as a simple toggle can quickly spiral into technical debt. Today, we’ll share with you how feature flags can go wrong (we’ve been there) and what you can do to keep them from becoming a problem.
Types of feature flags and their scope
Before we dive into the benefits, let’s clear something up: not all feature flags are just simple on/off switches. While boolean flags (true/false) are the most common — and the ones we’ll focus on in this article — there are other types you’ll find in real-world systems.
Some flags control gradual rollouts, activating a feature for just 10%, 25%, or 50% of users.
Others deliver dynamic values like strings, numbers, or configurations. For example, you might use a flag to decide whether a pricing tier is “basic”, “pro”, or “enterprise”, or to adjust some other parameter of your application.
These advanced flags can be powerful, but they also come with more complexity and risk. A string-based flag might break functionality if the input is misspelled (like setting "enabled" as "enabeld"), or if a developer expects "dark_mode" but gets "darkmode" instead. Since they rely on exact matches, they leave more room for human error.
Number-based flags can lead to inconsistencies if ranges or defaults aren’t clearly defined. And while percentage rollouts are great for testing at scale, they require good tooling to ensure users have a consistent experience.
That’s why in this article, we’re zooming in on boolean flags — the simplest and most widely used type. They’re incredibly useful, but also the easiest to accumulate and forget about, making them a common source of technical debt when not managed properly.
Feature flags benefits: why we use them (and why you should too)
Feature flags help us ship fast, test safely, and roll back changes instantly. Instead of pushing updates to everyone at once, we control who sees what - reducing risk and increasing flexibility. Sounds perfect, right? We think so too.
But if not handled properly, feature flags can become a mess. Here’s why we rely on them every day - and where they can go wrong.
1. Ship faster without losing control
We’ve all been there - rushing to deploy a new feature while dreading the potential fallout. Feature flags let us separate deployment from release, meaning we can ship code without exposing it to all users right away. This keeps our workflow smooth, prevents stale branches, and gives our product teams more control over launches.

2. Minimize risk with instant rollbacks
No matter how good your QA process is, things break. A buggy release can frustrate users or, worse, cause real damage. With feature flags, we don’t need emergency fixes or last-minute deploys to revert a bad release. We just turn off the flag, and problem solved.
3. Test in production without fear
Staging environments are useful but never quite match production. That’s why we use feature flags to test in the real world - with real data, real users, and real infrastructure. We also run A/B tests to see what works best before committing to a final version.

4. Control who gets access (without writing extra code)
Sometimes, a feature isn’t for everyone - yet. Feature flags act as built-in permission gates, letting us control access without modifying the codebase. No need for extra admin panels or complicated logic.

Feature flags risks: when they become a problem
If we weren’t clear enough: we love feature flags. They give us control, flexibility, and speed. But they also come with a cost. If you don’t manage them properly, they start piling up, turning into a mess that slows development instead of speeding it up. Here’s what happens when feature flags go wrong:
1. Code becomes harder to read and maintain
Every feature flag adds a conditional path to your code. Add enough of them, and suddenly you’re dealing with a tangled web of “if this, then that” logic. This increases your cyclomatic complexity - a measure of how many independent paths exist through your code. The higher it gets, the harder it becomes to test, debug, and safely refactor. What started as a clean, maintainable codebase slowly turns into a maze that only the original developer can navigate (if you’re lucky).
2. Stale flags = hidden technical debt
Unused feature flags are like leftovers in the fridge: you forget about them until they start to stink. These are flags that once controlled a feature but are now irrelevant because the feature is fully rolled out. Since the flag always returns the same value, it serves no purpose, yet it remains in the code, adding unnecessary complexity.
Cleaning up unused flags should be part of your workflow, but let’s be honest - most teams don’t do it regularly. Over time, these stale flags pile up, making the codebase harder to maintain and increasing the risk of unexpected behavior.
3. Testing becomes a nightmare
Every feature flag introduces an alternate execution path, and the more flags you have, the more testing scenarios you need to cover. A single feature with two flags creates four possible outcomes. Add a few more, and suddenly, your QA team is dealing with an explosion of test cases. Ensuring that every combination works correctly becomes overwhelming, and the likelihood of missing an edge case increases. Bugs slip through because no one has the time (or patience) to test every possible flag state.
It gets worse in production. A feature might work perfectly in staging, but when combined with real user data and different flag configurations, unexpected issues arise. Debugging becomes a challenge because reproducing the exact conditions that led to a bug is difficult when multiple flags are interacting. Without a clear strategy for managing and testing flags, teams risk deploying code that behaves unpredictably across different environments and users.
4. Performance can take a hit
Each flag adds a small conditional check to your code. On its own, it’s negligible. But when you’re evaluating dozens - or even hundreds - of flags on every request, it can start to add up, especially in performance-critical systems. It’s not usually a dealbreaker, but it’s worth keeping an eye on. Optimizing flag usage and cleaning up unused ones helps keep your app running lean and responsive.
When feature flags become technical debt
Technical debt happens when quick solutions today create bigger problems tomorrow (we have already talked about it). Feature flags, if left unchecked, are a perfect example. They start as a smart way to manage rollouts, but when teams fail to remove them, they turn into unnecessary clutter that makes the codebase harder to navigate, test, and debug.

A feature flag that’s fully rolled out and always set to “on” or “off” is no longer doing anything - but it’s still there, adding noise. Over time, these stale flags accumulate, making it difficult for developers to understand which parts of the code are actually in use.
The bigger problem? No one wants to remove them because they’re afraid of breaking something. This leads to hesitation, and before you know it, your code is full of outdated logic that no one fully understands.
Debugging and refactoring become a headache
Long-lived feature flags increase complexity, creating hidden dependencies and making it harder to track how a system behaves. When a bug appears, developers waste time trying to figure out whether a flag is influencing the issue. Refactoring becomes riskier too (removing old logic is harder when you don’t know if a flag is still relevant).
Every time a developer reads through code, they have to mentally parse which flags are active, which are deprecated, and what conditions they control. The more flags you have, the more mental overhead is required. This slows down development, increases onboarding time for new engineers, and makes maintaining the system unnecessarily complex.
Ignoring stale flags can still cause unexpected issues, though the risk depends on how feature flags are managed. If you're using an external platform, accidental resets are less likely unless someone manually changes a flag when they shouldn't. However, in systems with flags stored in code or databases, deployments can unintentionally override expected values, leading to unintended rollbacks or inconsistencies. In any case, keeping unused flags in the system adds unnecessary complexity and increases the chance of human error.
Cleaning up feature flags before they become a problem
Staying on top of feature flags is just as important as using them wisely. The longer a flag sticks around past its usefulness, the higher the risk of it turning into technical debt. In the next section, we’ll look at best practices for keeping feature flags under control - so they remain an asset, not a liability.
Best Practices to Avoid Feature Flag Debt
Yep, if you don’t manage them properly, they become a hidden source of technical debt, cluttering your codebase and making development slower and riskier. Here’s how to keep your feature flags under control:
1. Use a clear naming convention
Flags should have names that make sense at a glance. Avoid cryptic names like FF123_do_not_delete_this_72 future developers won’t know what it does or whether it’s safe to remove. A good rule of thumb: flag names should describe their purpose and be easy to understand without context.
It also helps to use prefixes or suffixes to organize flags by feature, platform, or domain. For example, a flag that controls a redesign on the dashboard might be named dashboard_redesign_enabled, while one specific to mobile users could be mobile_payments_enabled. This kind of structure makes flags easier to find, manage, and eventually clean up when they’re no longer needed.
✅ Example: instead of FF123_do_not_delete_this_72, use dashboard_is_redesign_enabled.
2. Set expiration dates and review flags regularly
Temporary flags should be treated like milk—they have an expiration date—. Set clear review dates for each flag, and check them at the end of every sprint or release cycle. If a flag has served its purpose, remove it.
✅ Practical tip: schedule a “Flag Cleanup Day” once a month where the team reviews and removes stale flags.
3. Track and monitor flags
It’s easy to lose track of flags, especially in large teams. Use monitoring tools to see which flags are still active and which have become stale. Dashboards, tagging systems, and automated reports can help keep everything visible.
✅ How to do it: use feature flag management tools that highlight flags marked as "Ready for removal" or "Inactive".
4. Define a flag lifecycle from day one
When you create a flag, you should already know when and how it will be removed. Make flag cleanup part of your team’s definition of “done”. A feature isn’t fully shipped until its flag is gone or marked as permanent.
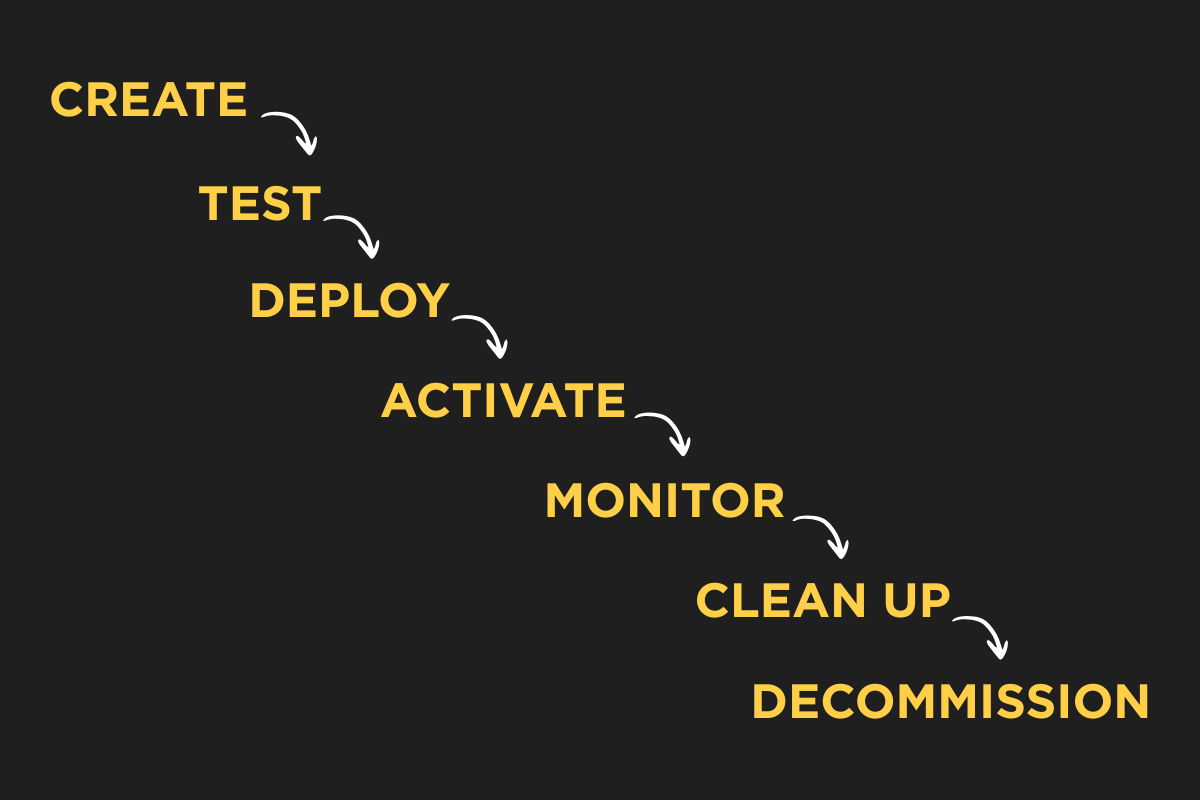
We’ve been there
We know how easy it is to let feature flags pile up. You’re moving fast, focused on shipping new features, and before you know it, your codebase is full of stale flags that no one remembers adding. We’ve had those moments - debugging a weird issue only to realize it’s caused by an old flag we forgot to remove. Cleaning up feature flags isn’t the most exciting task, but trust us, ignoring them only makes things worse.
The good news? A little discipline goes a long way. Set expiration dates, track your flags, and make cleanup part of your workflow. Future you (and your whole dev team) will thank you.
Want to learn more about managing technical debt, improving deployments, or scaling your digital product? At Acid Tango, we’re always up for a chat about building better software.